没有维护过oracle 8\9那个版本时,可能不会太接触这个热备份模式, 这个技术已经被RMAN所替代很多年,但是就是这个东西,让我们在最近一次19c 数据库故障中走了弯路, 数据库的内部某个机制触发了begin backup, 因为异常crash后又归档缺失,还尝试从备份做了恢复,最终还是使用bbed修改数据文件头异常恢复 ,目前为什么会处于备份模式还没有查到原因,不过提醒一下记的检查数据库是否有存在hot backup mode的文件,并分享什么是hot backup mode.
下面模拟一下 19c 多租户,注意如果做了重建控制文件,PDB名就显示为未知了,无法切换PDB,在第一次Open CDB时pdb名会自动找回。
[oracle@oel7db1 ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sun Aug 2 04:44:15 2020
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
SQL> alter database archivelog;
Database altered.
SQL> alter database open;
Database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 PDB1 MOUNTED
SQL> alter pluggable database pdb1 open;
Pluggable database altered.
SQL> select * from v$backup;
FILE# STATUS CHANGE# TIME CON_ID
---------- ------------------ ---------- --------- ----------
1 NOT ACTIVE 0 1
3 NOT ACTIVE 0 1
4 NOT ACTIVE 0 1
5 NOT ACTIVE 0 2
6 NOT ACTIVE 0 2
7 NOT ACTIVE 0 1
8 NOT ACTIVE 0 2
9 NOT ACTIVE 0 3
10 NOT ACTIVE 0 3
11 NOT ACTIVE 0 3
12 NOT ACTIVE 0 3
182 NOT ACTIVE 0 3
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status from v$containers a,v$datafile b where a.con_id=b.con_id order by
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- ---------- ---------- ---------- ------------------ ------------------- -------
2 PDB$SEED 8 9 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 6 4 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 5 1 2144549 2020-03-20 06:14:40 SYSTEM
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
1 CDB$ROOT 4 4 5061692 2020-08-02 04:45:04 ONLINE
1 CDB$ROOT 3 3 5061692 2020-08-02 04:45:04 ONLINE
1 CDB$ROOT 1 1 5061692 2020-08-02 04:45:04 SYSTEM
1 CDB$ROOT 7 7 5061692 2020-08-02 04:45:04 ONLINE
3 PDB1 10 4 5062895 2020-08-02 04:46:20 ONLINE
3 PDB1 11 9 5062895 2020-08-02 04:46:20 ONLINE
3 PDB1 12 12 5062895 2020-08-02 04:46:20 ONLINE
3 PDB1 9 1 5062895 2020-08-02 04:46:20 SYSTEM
12 rows selected.
SQL> alter database begin backup;
Database altered.
SQL> @log
Show redo log layout from V$LOG, V$STANDBY_LOG and V$LOGFILE...
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME NEXT_CHANGE# NEXT_TIME
---------- ---------- ---------- ---------- ---------- ---------- --- ---------------- ------------------ ------------------- ---------------------- ----------
1 1 31 209715200 512 1 YES INACTIVE 4920596 2020-07-28 05:04:50 5027660 2020-07-28
2 1 32 209715200 512 1 NO CURRENT 5027660 2020-07-28 23:10:19 18446744073709551615
3 1 30 209715200 512 1 YES INACTIVE 4806829 2020-07-21 23:13:41 4920596 2020-07-28
SQL> alter system switch logfile;
System alered.
SQL> alter system switch logfile;
System altered.
SQL> alter system switch logfile;
System altered.
SQL> @log
Show redo log layout from V$LOG, V$STANDBY_LOG and V$LOGFILE...
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME NEXT_CHANGE# NEXT_TIME
---------- ---------- ---------- ---------- ---------- ---------- --- ---------------- ------------------ ------------------- ---------------------- ----------
1 1 34 209715200 512 1 YES INACTIVE 5063932 2020-08-02 04:51:47 5063936 2020-08-02
2 1 35 209715200 512 1 NO CURRENT 5063936 2020-08-02 04:51:49 18446744073709551615
3 1 33 209715200 512 1 YES INACTIVE 5063929 2020-08-02 04:51:45 5063932 2020-08-02
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status from v$containers a,v$datafile b where a.con_id=b.con_id order b
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- ---------- ---------- ---------- ------------------ ------------------- -------
2 PDB$SEED 8 9 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 6 4 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 5 1 2144549 2020-03-20 06:14:40 SYSTEM
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
3 PDB1 10 4 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 11 9 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 12 12 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 9 1 5063905 2020-08-02 04:51:25 SYSTEM
1 CDB$ROOT 4 4 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 3 3 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 1 1 5063905 2020-08-02 04:51:25 SYSTEM
1 CDB$ROOT 7 7 5063905 2020-08-02 04:51:25 ONLINE
12 rows selected.
SQL> alter system checkpoint;
System altered.
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status from v$containers a,v$datafile b where a.con_id=b.con_id order b
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- ---------- ---------- ---------- ------------------ ------------------- -------
2 PDB$SEED 8 9 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 6 4 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 5 1 2144549 2020-03-20 06:14:40 SYSTEM
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
3 PDB1 10 4 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 11 9 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 12 12 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 9 1 5063905 2020-08-02 04:51:25 SYSTEM
1 CDB$ROOT 4 4 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 3 3 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 1 1 5063905 2020-08-02 04:51:25 SYSTEM
1 CDB$ROOT 7 7 5063905 2020-08-02 04:51:25 ONLINE
SQL> @dbinfo
DBID NAME CREATED LOG_MODE CHECKPOINT_CHANGE# OPEN_MODE FORCE_LOGGING
---------- ---------- ------------------- ------------ ------------------ -------------------- ---------------------------------------
3414393273 ANBOB19C 2020-03-20 05:43:21 ARCHIVELOG 5063984 READ WRITE NO
SQL> shut immediate
ORA-01149: cannot shutdown - file 1 has online backup set
ORA-01110: data file 1: '/u01/app/oracle/oradata/ANBOB19C/system01.dbf'
SQL> shut abort
ORACLE instance shut down.
[oracle@oel7db1 dbs]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sun Aug 2 05:06:44 2020
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup
ORACLE instance started.
Total System Global Area 1073738888 bytes
Fixed Size 9143432 bytes
Variable Size 792723456 bytes
Database Buffers 268435456 bytes
Redo Buffers 3436544 bytes
Database mounted.
ORA-10873: file 1 needs to be either taken out of backup mode or media recovered
ORA-01110: data file 1: '/u01/app/oracle/oradata/ANBOB19C/system01.dbf'
SQL> @log
Show redo log layout from V$LOG, V$STANDBY_LOG and V$LOGFILE...
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME NEXT_CHANGE# NEXT_TIME
---------- ---------- ---------- ---------- ---------- ---------- --- ---------------- ------------------ ------------------- ---------------------- ----------
1 1 37 209715200 512 1 NO CURRENT 5063951 2020-08-02 04:52:15 18446744073709551615
2 1 35 209715200 512 1 YES INACTIVE 5063936 2020-08-02 04:51:49 5063947 2020-08-02
3 1 36 209715200 512 1 YES INACTIVE 5063947 2020-08-02 04:52:13 5063951 2020-08-02
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status from
v$containers a,v$datafile b where a.con_id=b.con_id order by
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- -------------------- ---------- ---------- ------------------ ------------------- -------
2 PDB$SEED 8 9 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 5 1 2144549 2020-03-20 06:14:40 SYSTEM
2 PDB$SEED 6 4 2144549 2020-03-20 06:14:40 ONLINE
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
3 PDB1 10 4 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 12 12 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 11 9 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 1 1 5063905 2020-08-02 04:51:25 SYSTEM
3 PDB1 9 1 5063905 2020-08-02 04:51:25 SYSTEM
1 CDB$ROOT 4 4 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 3 3 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 7 7 5063905 2020-08-02 04:51:25 ONLINE
12 rows selected.
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status
from v$containers a,v$datafile_header b where a.con_id=b.con_id o
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- -------------------- ---------- ---------- ------------------ ------------------- -------
2 PDB$SEED 8 9 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 5 1 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 6 4 2144549 2020-03-20 06:14:40 ONLINE
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
3 PDB1 10 4 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 12 12 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 11 9 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 1 1 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 9 1 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 4 4 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 3 3 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 7 7 5063905 2020-08-02 04:51:25 ONLINE
12 rows selected.
SQL> alter database datafile 1 end backup;
Database altered.
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status from v$containers a,v$datafile_header b where a.con_id=b.con_id o
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- -------------------- ---------- ---------- ------------------ ------------------- -------
2 PDB$SEED 8 9 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 5 1 2144549 2020-03-20 06:14:40 ONLINE
2 PDB$SEED 6 4 2144549 2020-03-20 06:14:40 ONLINE
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
3 PDB1 10 4 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 12 12 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 11 9 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 9 1 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 4 4 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 3 3 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 7 7 5063905 2020-08-02 04:51:25 ONLINE
1 CDB$ROOT 1 1 5063984 2020-08-02 04:53:31 ONLINE
12 rows selected.
SQL> alter database datafile 9 end backup;
alter database datafile 9 end backup
*
ERROR at line 1:
ORA-01516: nonexistent log file, data file, or temporary file "9" in the current container
SQL> alter pluggable database datafile 9 end backup;
alter pluggable database datafile 9 end backup
*
ERROR at line 1:
ORA-01109: database not open
SQL> @cc pdb1;
ALTER SESSION SET container = pdb1;
Session altered.
--如果重建了控制文件,这一步就没法做了,因为pdb名字未知.
SQL> alter pluggable database datafile 9 end backup;
Pluggable database altered.
SQL> alter database datafile 11 end backup;
Database altered.
SQL> select a.con_id,a.name,b.file#,b.rfile#,b.checkpoint_change#,b.checkpoint_time,b.status from v$containers a,v$datafile_header b where a.con_id=b.con_id o
CON_ID NAME FILE# RFILE# CHECKPOINT_CHANGE# CHECKPOINT_TIME STATUS
---------- -------------------- ---------- ---------- ------------------ ------------------- -------
3 PDB1 182 181 4102092 2020-06-16 05:25:52 ONLINE
3 PDB1 10 4 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 12 12 5063905 2020-08-02 04:51:25 ONLINE
3 PDB1 11 9 5063984 2020-08-02 04:53:31 ONLINE
3 PDB1 9 1 5063984 2020-08-02 04:53:31 ONLINE
使用bbed对比begin backup还没有结束的和已经end backup的两个文件头
SQL> select file#,name from v$datafile;
FILE# NAME
---------- -------------------------------------------------------
9 /u01/app/oracle/oradata/ANBOB19C/pdb1/system01.dbf
10 /u01/app/oracle/oradata/ANBOB19C/pdb1/sysaux01.dbf
11 /u01/app/oracle/oradata/ANBOB19C/pdb1/undotbs01.dbf
12 /u01/app/oracle/oradata/ANBOB19C/pdb1/users01.dbf
182 /u01/app/oracle/oradata/ANBOB19C/pdb1/tbs101.dbf
SQL> select to_char(5063984,'xxxxxxxxxxxx') from dual;
TO_CHAR(50639
-------------
4d4530
SQL> select to_char(5063905,'xxxxxxxxxxxx') from dual;
TO_CHAR(50639
-------------
4d44e1
-- file 10#
[oracle@oel7db1 ~]$ bbed blocksize=8192 mode=edit filename=/u01/app/oracle/oradata/ANBOB19C/pdb1/sysaux01.dbf
Password:
BBED: Release 2.0.0.0.0 - Limited Production on Sun Aug 2 05:22:14 2020
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
************* !!! For Oracle Internal Use only !!! ***************
BBED> p kcvfh
struct kcvfh, 1272 bytes @0
struct kcvfhbfh, 20 bytes @0
ub1 type_kcbh @0 0x0b
ub1 frmt_kcbh @1 0xa2
ub2 wrp2_kcbh @2 0x0000
ub4 rdba_kcbh @4 0x01000001
ub4 bas_kcbh @8 0x00000000
ub2 wrp_kcbh @12 0x0000
ub1 seq_kcbh @14 0x01
ub1 flg_kcbh @15 0x04 (KCBHFCKV)
ub2 chkval_kcbh @16 0xb992
ub2 spare3_kcbh @18 0x0000
struct kcvfhhdr, 76 bytes @20
ub4 kccfhswv @20 0x00000000
ub4 kccfhcvn @24 0x13000000
ub4 kccfhdbi @28 0xcb8381b9
text kccfhdbn[0] @32 A
text kccfhdbn[1] @33 N
text kccfhdbn[2] @34 B
text kccfhdbn[3] @35 O
text kccfhdbn[4] @36 B
text kccfhdbn[5] @37 1
text kccfhdbn[6] @38 9
text kccfhdbn[7] @39 C
ub4 kccfhcsq @40 0x00003330
ub4 kccfhfsz @44 0x0000c800
s_blkz kccfhbsz @48 0x00
ub2 kccfhfno @52 0x000a
ub2 kccfhtyp @54 0x0003
ub4 kccfhacid @56 0x00000000
ub4 kccfhcks @60 0x00000000
text kccfhtag[0] @64
text kccfhtag[1] @65
text kccfhtag[2] @66
text kccfhtag[3] @67
text kccfhtag[4] @68
text kccfhtag[5] @69
text kccfhtag[6] @70
text kccfhtag[7] @71
text kccfhtag[8] @72
text kccfhtag[9] @73
text kccfhtag[10] @74
text kccfhtag[11] @75
text kccfhtag[12] @76
text kccfhtag[13] @77
text kccfhtag[14] @78
text kccfhtag[15] @79
text kccfhtag[16] @80
text kccfhtag[17] @81
text kccfhtag[18] @82
text kccfhtag[19] @83
text kccfhtag[20] @84
text kccfhtag[21] @85
text kccfhtag[22] @86
text kccfhtag[23] @87
text kccfhtag[24] @88
text kccfhtag[25] @89
text kccfhtag[26] @90
text kccfhtag[27] @91
text kccfhtag[28] @92
text kccfhtag[29] @93
text kccfhtag[30] @94
text kccfhtag[31] @95
ub4 kcvfhrdb @96 0x00400208
struct kcvfhcrs, 8 bytes @100
ub4 kscnbas @100 0x0020bdd8
ub2 kscnwrp @104 0x8000
ub2 kscnwrp2 @106 0x0000
ub4 kcvfhcrt @108 0x3db8e18f
ub4 kcvfhrlc @112 0x3db8d9fe
struct kcvfhrls, 8 bytes @116
ub4 kscnbas @116 0x001d4fd1
ub2 kscnwrp @120 0x8000
ub2 kscnwrp2 @122 0x0000
ub4 kcvfhbti @124 0x3e6d6b4d
struct kcvfhbsc, 8 bytes @128
ub4 kscnbas @128 0x004d44e1
ub2 kscnwrp @132 0x8000
ub2 kscnwrp2 @134 0x0000
ub2 kcvfhbth @136 0x0001
ub2 kcvfhsta @138 0x0001 (KCVFHHBP)
struct kcvfhckp, 36 bytes @484
struct kcvcpscn, 8 bytes @484
ub4 kscnbas @484 0x004d44e1
ub2 kscnwrp @488 0x8000
ub2 kscnwrp2 @490 0x0000
ub4 kcvcptim @492 0x3e6d6b4d
ub2 kcvcpthr @496 0x0001
union u, 12 bytes @500
struct kcvcprba, 12 bytes @500
ub4 kcrbaseq @500 0x00000020
ub4 kcrbabno @504 0x000216d6
ub2 kcrbabof @508 0x0010
ub1 kcvcpetb[0] @512 0x02
ub1 kcvcpetb[1] @513 0x00
ub1 kcvcpetb[2] @514 0x00
ub1 kcvcpetb[3] @515 0x00
ub1 kcvcpetb[4] @516 0x00
ub1 kcvcpetb[5] @517 0x00
ub1 kcvcpetb[6] @518 0x00
ub1 kcvcpetb[7] @519 0x00
ub4 kcvfhcpc @140 0x0000008f
ub4 kcvfhrts @144 0x3e5e9ba4
ub4 kcvfhccc @148 0x0000008e
struct kcvfhbcp, 36 bytes @152
struct kcvcpscn, 8 bytes @152
ub4 kscnbas @152 0x004d4530
ub2 kscnwrp @156 0x8000
ub2 kscnwrp2 @158 0x0000
ub4 kcvcptim @160 0x3e6d6bcb
ub2 kcvcpthr @164 0x0001
union u, 12 bytes @168
struct kcvcprba, 12 bytes @168
ub4 kcrbaseq @168 0x00000025
ub4 kcrbabno @172 0x00000003
ub2 kcrbabof @176 0x0010
ub1 kcvcpetb[0] @180 0x02
ub1 kcvcpetb[1] @181 0x00
ub1 kcvcpetb[2] @182 0x00
ub1 kcvcpetb[3] @183 0x00
ub1 kcvcpetb[4] @184 0x00
ub1 kcvcpetb[5] @185 0x00
ub1 kcvcpetb[6] @186 0x00
ub1 kcvcpetb[7] @187 0x00
ub4 kcvfhbhz @312 0x0000c800
struct kcvfhxcd, 16 bytes @316
ub4 space_kcvmxcd[0] @316 0x00000000
ub4 space_kcvmxcd[1] @320 0x00000000
ub4 space_kcvmxcd[2] @324 0x00000000
ub4 space_kcvmxcd[3] @328 0x00000000
sword kcvfhtsn @332 1
ub2 kcvfhtln @336 0x0006
text kcvfhtnm[0] @338 S
text kcvfhtnm[1] @339 Y
text kcvfhtnm[2] @340 S
text kcvfhtnm[3] @341 A
text kcvfhtnm[4] @342 U
text kcvfhtnm[5] @343 X
text kcvfhtnm[6] @344
text kcvfhtnm[7] @345
text kcvfhtnm[8] @346
text kcvfhtnm[9] @347
text kcvfhtnm[10] @348
text kcvfhtnm[11] @349
text kcvfhtnm[12] @350
text kcvfhtnm[13] @351
text kcvfhtnm[14] @352
text kcvfhtnm[15] @353
text kcvfhtnm[16] @354
text kcvfhtnm[17] @355
text kcvfhtnm[18] @356
text kcvfhtnm[19] @357
text kcvfhtnm[20] @358
text kcvfhtnm[21] @359
text kcvfhtnm[22] @360
text kcvfhtnm[23] @361
text kcvfhtnm[24] @362
text kcvfhtnm[25] @363
text kcvfhtnm[26] @364
text kcvfhtnm[27] @365
text kcvfhtnm[28] @366
text kcvfhtnm[29] @367
ub4 kcvfhrfn @368 0x00000004
struct kcvfhrfs, 8 bytes @372
ub4 kscnbas @372 0x00000000
ub2 kscnwrp @376 0x0000
ub2 kscnwrp2 @378 0x0000
ub4 kcvfhrft @380 0x00000000
struct kcvfhafs, 8 bytes @384
ub4 kscnbas @384 0x00000000
ub2 kscnwrp @388 0x0000
ub2 kscnwrp2 @390 0x0000
ub4 kcvfhbbc @392 0x00000000
ub4 kcvfhncb @396 0x00000000
ub4 kcvfhmcb @400 0x00000000
ub4 kcvfhlcb @404 0x00000000
ub4 kcvfhbcs @408 0x00000000
ub2 kcvfhofb @412 0x0000
ub2 kcvfhnfb @414 0x0000
ub4 kcvfhprc @416 0x3bf3129f
struct kcvfhprs, 8 bytes @420
ub4 kscnbas @420 0x00000001
ub2 kscnwrp @424 0x0000
ub2 kscnwrp2 @426 0x0000
struct kcvfhprfs, 8 bytes @428
ub4 kscnbas @428 0x00000000
ub2 kscnwrp @432 0x0000
ub2 kscnwrp2 @434 0x0000
ub4 kcvfhtrt @444 0x00000000
BBED>
# file 9#
BBED> set filename '/u01/app/oracle/oradata/ANBOB19C/pdb1/system01.dbf';
FILENAME /u01/app/oracle/oradata/ANBOB19C/pdb1/system01.dbf
-- like above
放到UE中对比差异,当然出了块地址还块号相关的,我们主要关注checkpoint相关.
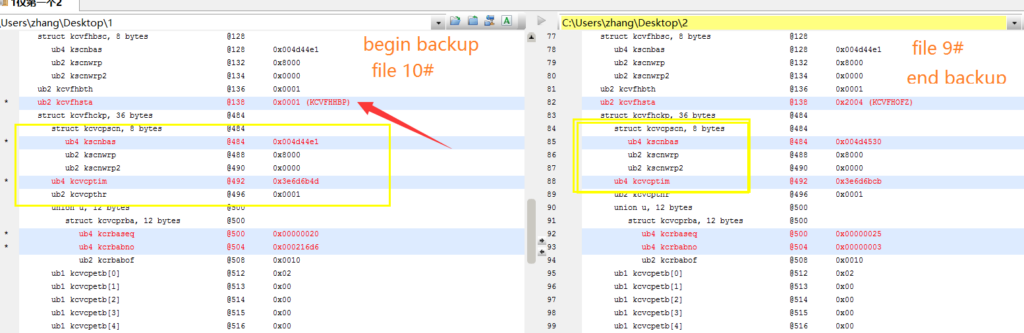
如果不做begin backup查询x$kcvfh.FHBCP_SCN默认为0否则不为0,当end backup时是 x$kcvfh.FHSCN=x$kcvfh.FHBCP_SCN。当然常规推scn 是无法解决的,使用bbed 修改kcvfhckp的SCN 为kcvfhbcp的SCN。当然数据文件多,可以使用bbed 复制该结构到不同数据文件如:
assign file 1 block 1 kcvfhckp = file 140 block 1 kcvfhckp
assign file 3 block 1 kcvfhckp = file 140 block 1 kcvfhckp
如果数据文件在ASM中可能又要麻烦一些,可以使得dbms_diskgroup提供的内部方法dbms_diskgroup.patchfile去传递ASM和文件系统的文件头块。
Checkpoint Count
Allow detection of a restored data file or control File
Incremented at every checkpoint
Checkpoint Structure
Records the last checkpoint information
Frozen when file is in hot backup mode
Backup checkpoint SCN
Updated during hot backups
Used in conjunction with the alter database end backup command
If the checkpoint count and the backup checkpoint structure match the information found in the control file , the end backup command succeeds and clears the hot backup fuzzy bit.
下一篇是hot backup MODE的知识。