OceanBase Database也同oracle一样支持partition table,但存在一些注意事项,甚至和oracle存在一些差异。分布式数据库的数据打散方式并不相同, 分布数据基于组规则到不同的物理区,在Oceanbase中以 Partition粒度分布到不同的OB SERVER节点,Oracle mode 的OceanBase Database可以创建65536个分区partition,也可以创建subpartition, Table的分区列又叫分区键( partitioning key), 分区键必须是PK和UK的子集或者是说主键唯一键必须包含分区键。
分区数据分布
在OB分区是数据同步的最小单元,每个分区的多副本组成一个独立的Paxos组,如果没有显示的创建分区表(non-partition),就可能认为只有1个分区。 默认业务只有leader副本提供读写服务,follower副本只同步数据不提供服务。特殊场景下,业务SQL使用弱一致性读 Hint(即read_consistency(weak))可以就近读取follower副本.
Paxos协议保证了Redo会在至少一个Follower副本同步(最终所有Follower副本一致)。多副本会跟OceanBase集群的rootservice服务维持心跳,当Leader副本不可用时,经过2个租约时间后rootservice会选举出新的Leader,应用一致新Leader提供读写服务。在OceanBase里,节点不分主从,同一节点中可能leader与flollwer混存,leader partition副本数据提供业务访问。
注,如果以下未表明Oceanbase MySQL Mode 均表示 Oracle mode。
分区格式
目前 Oracle mode of OceanBase Database支持分区类型:
- RANGE partitioning
- LIST partitioning
- HASH partitioning
- Composite partitioning
分区名转换 Partition naming conventions
对于LIST或range分区表,分区名称在创建表时指定。Hash 分区表不允许制定分区名,在OB V3不支持raname partition(重命名), 对于依赖分区名的逻辑影响比较大,如果分区名错误仅删除后 重建。 V4已支持rename 。
分区转换 Convert non-partitioned into partitioned
在OB V4中可以像oracle一样支持通过DDL的方式,在非分区表与分区表(子分区表)之间转换
| Partitioning method | Non-partitioning | Partitioning | Subpartitioning |
|---|---|---|---|
| Non-partitioning | – | Supported | Supported |
| Partitioning | Not supported | – | Not supported |
| Subpartitioning | Not supported | Not supported | – |
样例如, 更多关注OB online doc obclient> ALTER TABLE tbl1 MODIFY PARTITION BY HASH(c1) PARTITIONS 4; Query OK, 0 rows affected obclient> ALTER TABLE tbl2 MODIFY PARTITION BY HASH(c1) SUBPARTITION BY RANGE(c2) SUBPARTITION template( SUBPARTITION p1 VALUES LESS THAN ('10-OCT-2016'), SUBPARTITION p2 VALUES LESS THAN ('30-OCT-2016')) PARTITIONS 2; Query OK, 0 rows affected
分区裁剪 Partition pruning
在OB中一样可以使用分区,避免访问无关分区减少无效读,提升SQL效率,同样要求SQL中包含分区键。 通过 EXPLAIN 查看执行计划可以看到分区裁剪的结果。
+------------------------------------------------------------------------------------+ | Query Plan | +------------------------------------------------------------------------------------+ | =============================================== | | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| | | ----------------------------------------------- | | |0 |TABLE FULL SCAN|TBL1|1 |4 | | | =============================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([TBL1.COL1], [TBL1.COL2]), filter([TBL1.COL1 = 1]), rowset=16 | | access([TBL1.COL1], [TBL1.COL2]), partitions(p1) | | is_index_back=false, is_global_index=false, filter_before_indexback[false], | | range_key([TBL1.__pk_increment]), range(MIN ; MAX)always true | +------------------------------------------------------------------------------------+
范围访问多分区的样式 access([T1.C1], [T1.C2]), partitions(p[0-4])
分区拆分 Parition Split
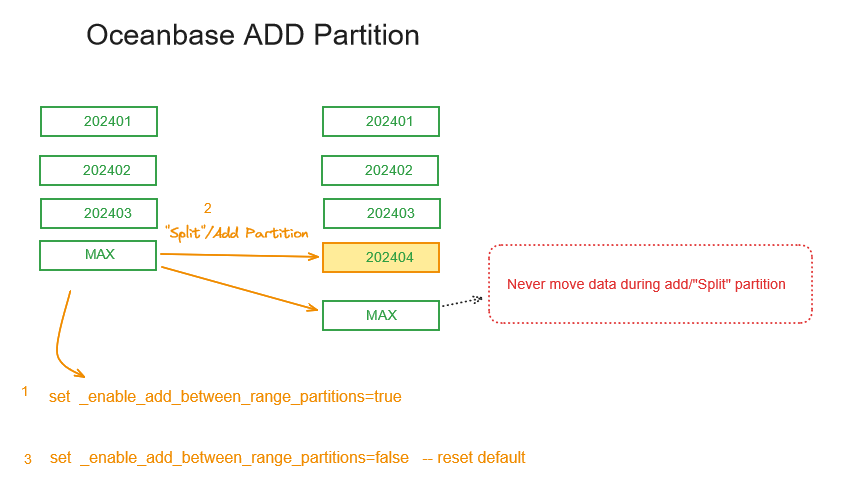
OceanBase 版本不支持split partition功能只能顺序的add分区, 在oracle中可以从大的分区split 分区,增加中间的分区,在OB后期的版本增加了_enable_add_between_range_partitions隐藏参数,做为一个临时增加中间分区的开关,但是实现当前还是不够完美,split partition DDL语句中关键字依旧是”add partition”。
在oracle 中
ALTER TABLE table_name SPLIT PARTITION old_partition
AT (new_high_bound) INTO (PARTITION new_partition TABLESPACE new_tablespace,
PARTITION old_partition)
而在oceanbase中
# check parameter value
select b.tenant_name,a.* from
__all_virtual_tenant_parameter_info a,__all_tenant b where
name = '_enable_add_between_range_partitions' and
b.tenant_id > 1000 and a.tenant_id=b.tenant_id order by
1,zone;,
# set parameter to true as root
alter system set _enable_add_between_range_partitions = 'True' tenant='xxx';
# add betwen partition, e.g.
ALTER TABLE table_name add partition new_partition values less than (new_high_bound);
# check partition
select * from dba_tab_partitions where ....
# restore parameter to false as root
alter system set _enable_add_between_range_partitions = 'False' tenant='xxx';
1, 因为add partition 不校验数据,有可能数据在OLD PARTITION中
2,该操作不像oracle移动数据,不会导致索引失效, BTW 在OB中如果索引失效,如drop partitionr的全局索引,索引没有rebuild语法,需要提前获取索引的创建DDL, drop index, 重新创建。
add between分区风险
对于每月有split partition需求的用户,add partition 区间分区是不校验数据存在一定风险, 我们一个客户半年时间因为这个问题出现2次核心数据库查询不一致。试想一下,如上图数据先入库进入到MAX partition, 然后拆分区202404, 但实际202404匹配的数据依旧在MAX partition, 而在查询时,如果SQL没使用分区裁剪,扫描到MAX 分区,数据是可以显示, 但是如果优化器使用了分区裁剪,根据分区定义仅在202404分区检索,会导致数据不显示, 这里就需要人为的修正数据,把数据重新insert并删除MAX中的202404数据。这个问题在Oracle中 partition 交换不校验数据也存在,9年前我分享了那个案例《数据去哪了?现实版 (partition data invalid)》
这问题究竟是谁的责任呢?
1, 业务数据入库时间与前期设计不符,前段应用未做数据校验,如来自未来时间的数据。
2,数据库split机制,拆分区add时,未自动检索下一个分区区间数据,并移动匹配数据到对应分区。
3,做split partition的DBA,在拆分add partition时,没有提前手动检索下一个分区的数据,但是像某些客户数据库每月有几十万个分区要split,这又是不现实的。
4,是否不该增加MAX分区,无效数据就不应该如库?
问题从源头上解决,建议1前台对有效数据做校验,2数据库增加SPLIT Partition并校验语法机制,或记录add between partition后台异步修正,3使用interval partition 自动创建分区, 4,人工仅做数据修复。
Reference
https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105739